

Remember the WABAC machine in the beloved The Adventures of Rocky and Bullwinkle and Friends show…the device that enabled Mr. Peabody and his pet boy Sherman to visit various pivotal moments in history? Pretty great stuff, wasn’t it?
Well, this post isn’t about that. Sorry *not sorry*.
Alert Gazette readers may recall — even without the aid of WABAC — that I toiled over a hot keyboard to restore some semblance of semi-coherence by fixing issues that caused historically important squirrel videos to not appear. In the process, I began to wonder just exactly when I posted the first video to this blog*. In order to find the answer to this Very Important Question, I had to turn to a real-life WABAC: the Internet Archive’s Wayback Machine.
Digression: Semi-sentient Gazette readers may wonder at this point…”why didn’t he just click over to the first posts via his own Archives Index?” Well, normally that would be an excellent strategy. But — little known fact — there was a brief period of time in the hazy past when *someone* made the ill-advised decision to terminate the Gazette. Said termination lasted only a few months, but when *someone* came to their senses, *someone* had the task of restoring history that had been lost. That history consisted of a couple of thousand posts, all of them QUITE SPECTACULAR (as you can imagine), but logistically there was no way to restore everything. Only a relative few select articles made the cut. The process by which this was accomplished was quite Biblical.
So, off to the Wayback Machine *someone* went.
By the way, the Internet Archive, which came into being in 1996, is a non-profit organization which, in its own words, “is building a digital library of Internet sites and other cultural artifacts in digital form. Like a paper library, we provide free access to researchers, historians, scholars, the print disabled, and the general public. Our mission is to provide Universal Access to All Knowledge.” All. Knowledge. Pretty impressive, although that does cause one to wonder why the Gazette would be included. Nevertheless, we press on.
The current archive, as of the date of this post, contains:
- 330 billion web pages
- 20 million books and texts
- 4.5 million audio recordings (including 180,000 live concerts)
- 4 million videos (including 1.6 million Television News programs)
- 3 million images
- 200,000 software programs
Included amongst this vast library of culturally significant digital artifacts are almost 50,000 “captures” of files that comprise the articles within the Gazette, spanning the period from April 1, 2003 to March 3, 2019. The summary statistics border on frightening in their detail: more than 36,000 text files, 12,000 images, 29 audio files, and thousands of linked URLs. In the interest of full disclosure, I have no idea what any of those statistics really mean, but they impress the heck out of me.
As it turned out, the Wayback archives were interesting (to me), but not all that helpful. They did bring back some fond memories, such as the changes in the Gazette’s layout over time, as shown below.

Here’s a snapshot of the Gazette’s initial layout on the dismal blogging platform creatively named “Blogger”
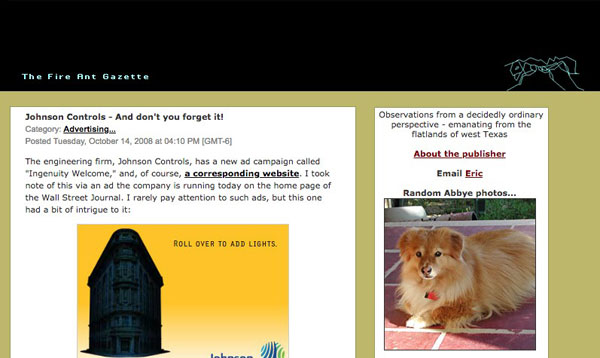
A later Gazette layout; this one was universally lauded because it displayed a different photo of Abbye every time the page was reloaded (my own very successful version of clickbait)

Another later early layout, this one from my short-lived “socially conscious” era before I became the completely cynical shell of a human being I am now. I stood with a “free Iran” for a few months until it dawned on me that Iran couldn’t care less. So much for the power of citizen journalists employing defiant header graphics.
Now that I’ve addressed the missing videos, I may start addressing the 349 broken links on past posts to see if they’re really worth tracking down and fixing. That’s approximately 8% of the total number of links I’ve included on the blog, not counting those in this post. How do I know this? Well, I dropped into another handy website, Broken Link Check, which told me that in the 2,163 pages of the Gazette that it crawled, it checked about 4,200 links. It also identified the broken ones, but it’s up to me to figure out why they’re broken and if they can even be fixed.
If my archeological dig through the internet archive taught me anything, it’s that just because you can preserve everything, it doesn’t mean you should.
*December 6, 2006.
Discover more from The Fire Ant Gazette
Subscribe to get the latest posts sent to your email.